
ไม่ว่าคุณจะกำลังพัฒนาแอปที่เพิ่งเริ่มต้นหรือให้บริการที่มีการเข้าชมสูงอยู่แล้วก็ตาม คุณจะได้รับประโยชน์จากข้อมูลเชิงลึกและคำแนะนำในคู่มือนี้เกี่ยวกับวิธีปรับขนาดบริการอย่างราบรื่นด้วย FCM แนวคิดและแนวทางปฏิบัติเหล่านี้จะช่วยคุณหลีกเลี่ยงผลกระทบด้านลบเมื่อคุณต้องส่งข้อความจำนวนมาก
คำและแนวคิดที่สำคัญ
คำขอข้อความ: คำขอข้อความ FCM ซึ่งใช้แทนกันได้กับ "คำขอ" "ข้อความ" หรือ "คำค้นหา"
คำขอต่อวินาที (RPS): เมตริกที่อธิบายอัตราคำขอขาเข้าไปยัง FCM ซึ่งใช้แทนกันได้กับคำค้นหาต่อวินาที (QPS)
โทเค็นโควต้า, บัคเก็ตโทเค็น และการเติม: เมื่อส่งข้อความเทียบกับ FCM HTTP v1 API คำขอแต่ละรายการจะใช้ โทเค็นโควต้า ที่จัดสรรไว้ในกรอบเวลาที่กำหนด กรอบเวลานี้เรียกว่า "บัคเก็ตโทเค็น" ซึ่งจะ เติม จนเต็มเมื่อสิ้นสุด กรอบเวลา ตัวอย่างเช่น HTTP v1 API จะจัดสรรโทเค็นโควต้า 6 แสนรายการสำหรับบัคเก็ตโทเค็นแต่ละรายการที่มีระยะเวลา 1 นาที ซึ่งจะเติมจนเต็มเมื่อสิ้นสุดกรอบเวลา 1 นาทีแต่ละรายการ
การจำกัดการส่งคำขอจากฝั่งเซิร์ฟเวอร์: เมื่อปริมาณการเข้าชมเกินความจุของบริการ FCM ระบบจะปฏิเสธคำขอที่เกินความจุในการให้บริการเพื่อจำกัดอัตราการไหลเข้า ระบบอาจแสดงการตอบกลับข้อผิดพลาด 429 พร้อมส่วนหัว retry-after เพื่อระบุว่าคุณควรรอระยะเวลาที่กำหนดก่อนที่จะลองส่งคำขออีกครั้ง
การจำกัดการส่งคำขอจากฝั่งไคลเอ็นต์: เมื่อไคลเอ็นต์พบข้อผิดพลาดของคำขอ เวลาในการตอบสนองสูง
หรือข้อผิดพลาด 429 ไคลเอ็นต์ควรจำกัดอัตราการไหลออกโดยสมัครใจเพื่อหลีกเลี่ยงไม่ให้
การจราจรติดขัดแย่ลง
Exponential Backoff: เมื่อลองส่งคำขอที่เกิดข้อผิดพลาดอีกครั้ง ให้เพิ่มการหน่วงเวลาแบบทวีคูณ เช่น 1 วินาที, 2 วินาที, 4 วินาที, 8 วินาที, 16 วินาที, 32 วินาที และอื่นๆ
Jittering: หลีกเลี่ยงการลองส่งคำขออีกครั้งในช่วงเวลาที่แน่นอน การใช้ Jittering จะช่วยให้คุณเปลี่ยนการหน่วงเวลาในการลองส่งคำขออีกครั้งผ่านกระบวนการแบบสุ่มเพื่อกระจายการหน่วงเวลาอย่างสม่ำเสมอเมื่อเวลาผ่านไป (เช่น 0.9 วินาที, 2.3 วินาที, 4.1 วินาที, 8.5 วินาที, 17.9 วินาที, 34.7 วินาที)
การขยายการลองส่งคำขออีกครั้ง: เมื่อลองส่งคำขอที่ล้มเหลวอีกครั้งโดยไม่มี Exponential Backoff/Jittering คำขอเหล่านั้นมักจะสะสมและเพิ่มภาระการเข้าชมที่กำลังเกิดขึ้น ซึ่งอาจ "ขยาย" และทำให้ปัญหาการจราจรติดขัดแย่ลง
ปัญหา: การเข้าชมที่เพิ่มขึ้นอย่างรวดเร็ว
FCM ประมวลผลคำขอหลายล้านรายการต่อวินาที (RPS) สาเหตุหลักที่ทำให้เกิดการจราจรติดขัดในระบบ ปัญหาเวลาในการตอบสนอง และการหยุดทำงานคือการเข้าชมที่เพิ่มขึ้นอย่างรวดเร็ว
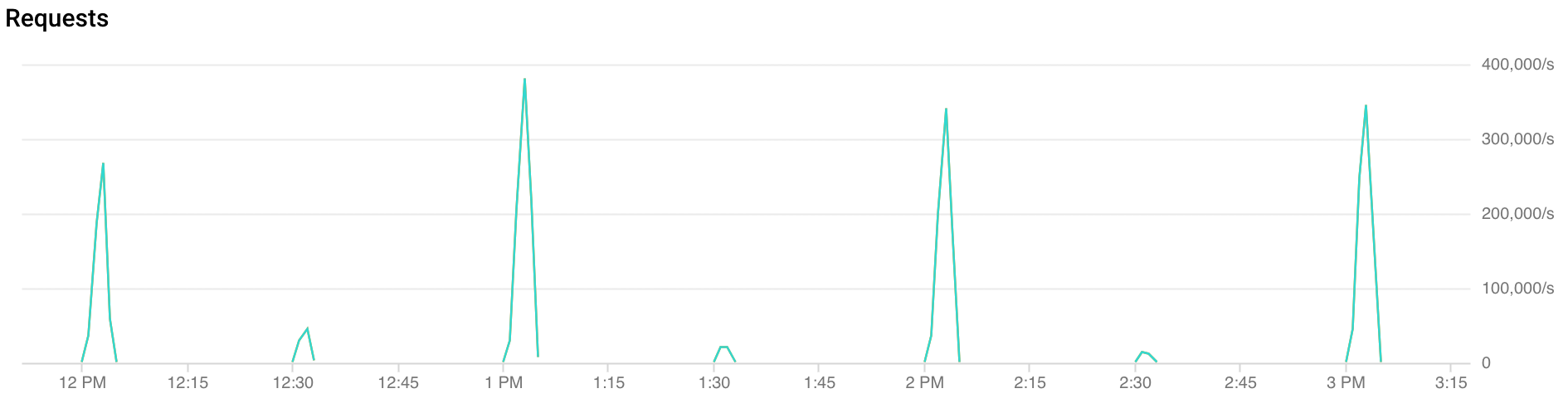
การเข้าชมที่เพิ่มขึ้นอย่างรวดเร็วคืออะไร
การเข้าชมที่เพิ่มขึ้นอย่างรวดเร็วมีหลายประเภท
การเข้าชมที่เพิ่มขึ้นอย่างรวดเร็วเมื่อขึ้นชั่วโมงใหม่: FCM ได้รับการเข้าชมมากกว่า 2 เท่าในช่วง 30 วินาทีถึง 2 นาทีแรกของแต่ละชั่วโมง นอกจากนี้ยังพบการเข้าชมที่เพิ่มขึ้นอย่างรวดเร็วในลักษณะที่คล้ายกันแต่มีปริมาณน้อยกว่าเมื่อผ่านไปครึ่งชั่วโมงและหนึ่งในสี่ของชั่วโมง (เช่น 00:15, 00:30, 00:45)
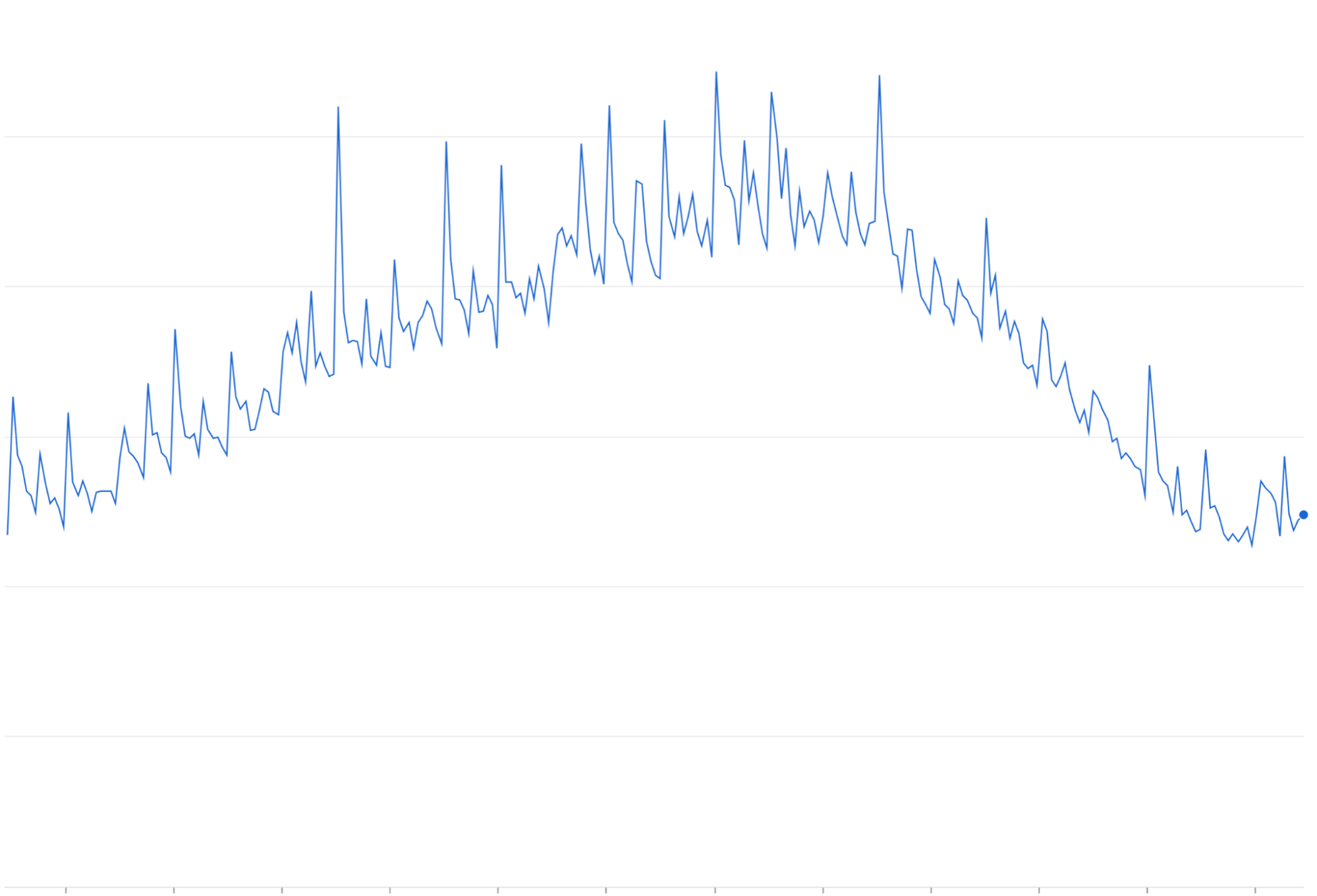
การขยายการลองส่งคำขออีกครั้ง: การลองส่งคำขอที่ล้มเหลวหรือหมดเวลาอีกครั้งโดยไม่มี Exponential Backoff อาจ สะสมเป็นคลื่นการเข้าชมที่เกิดขึ้นซ้ำๆ นอกเหนือจากการเข้าชมที่เพิ่มขึ้นอยู่แล้ว
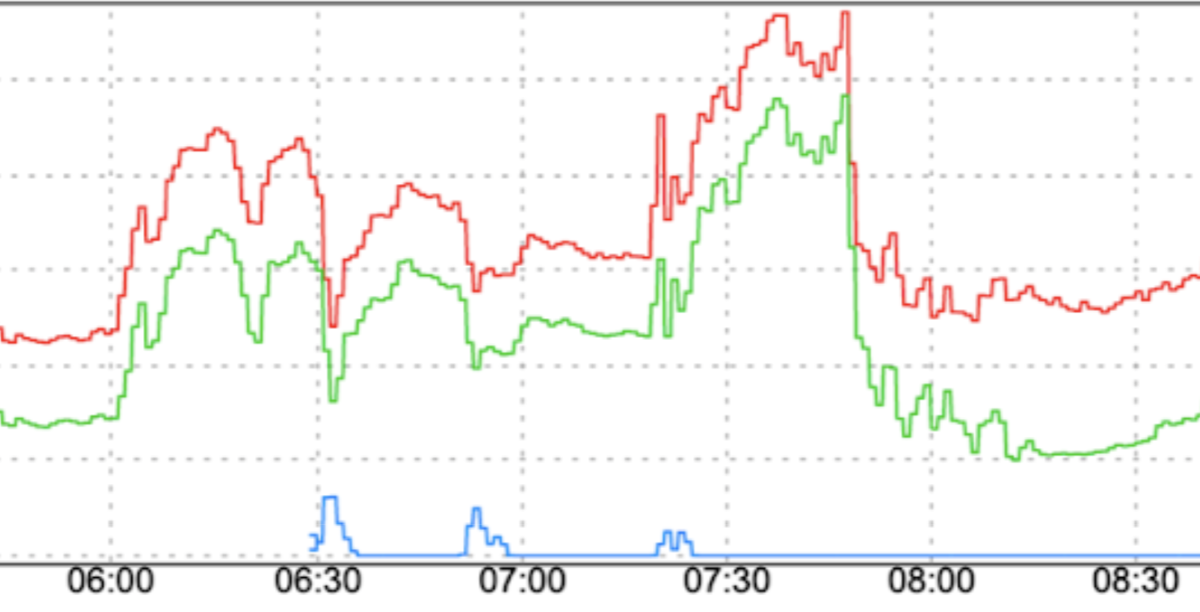
การเปลี่ยนแปลงรูปแบบการเข้าชมอย่างกะทันหัน: การนำการเข้าชมใหม่ไปยัง FCM หรือการย้ายการเข้าชมไปยัง FCM ในภูมิภาคต่างๆ โดยไม่มีปัจจัยที่ช่วยให้การเปลี่ยนแปลงราบรื่น เช่น การเพิ่มขึ้นอย่างค่อยเป็นค่อยไป อาจทำให้เกิดการเข้าชมที่เพิ่มขึ้นอย่างรวดเร็ว
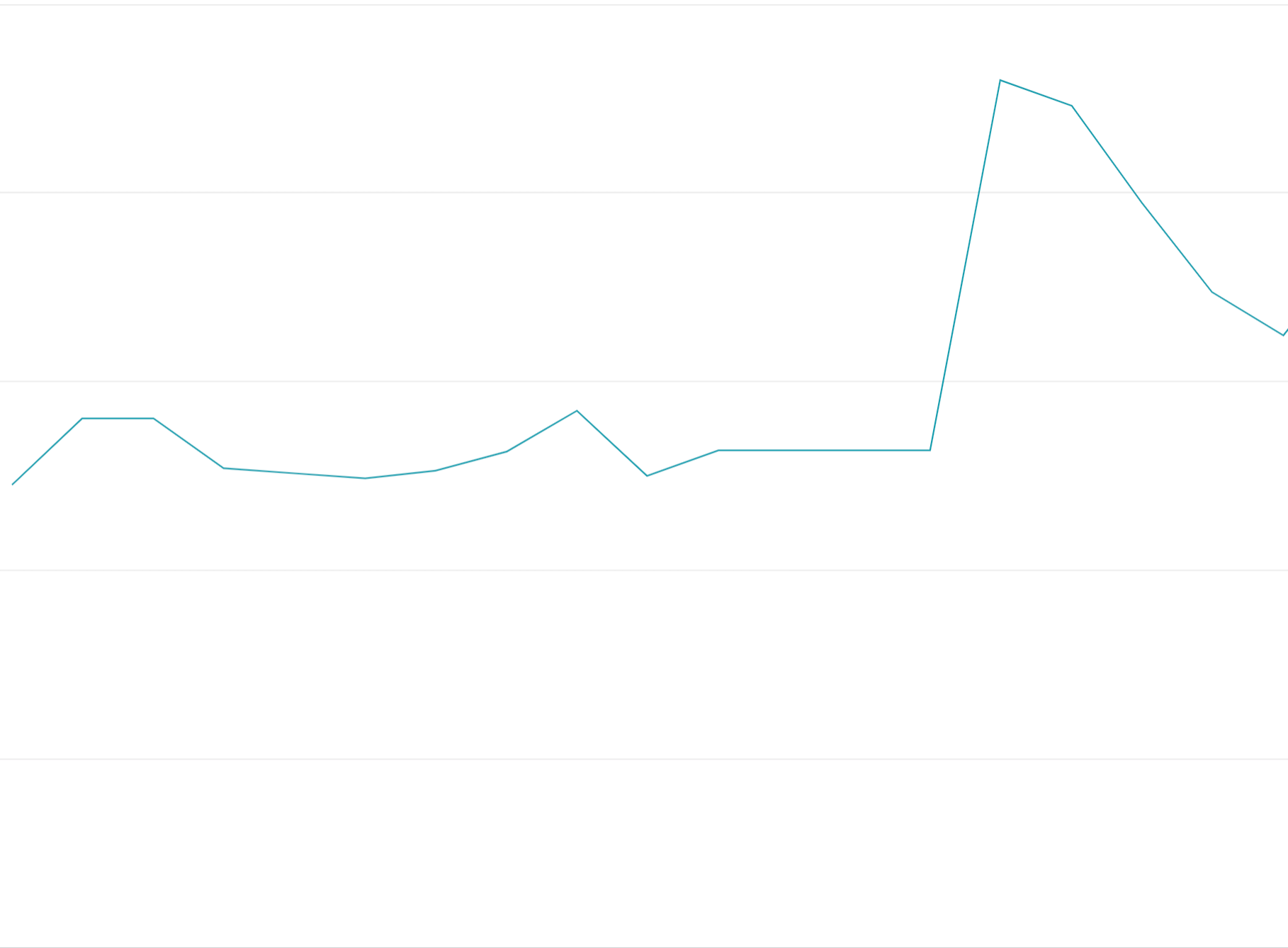
การใช้โทเค็นโควต้าล่วงหน้า: การใช้โทเค็นโควต้าทั้งหมดจนหมดในช่วงเริ่มต้นของกรอบเวลาโควต้าแทนที่จะกระจายคำขออย่างสม่ำเสมอในกรอบเวลาโควต้าจะทำให้เกิดการแกว่งแบบเปิดและปิดซึ่งยากและมีค่าใช้จ่ายสูงในการปรับสมดุลโหลด
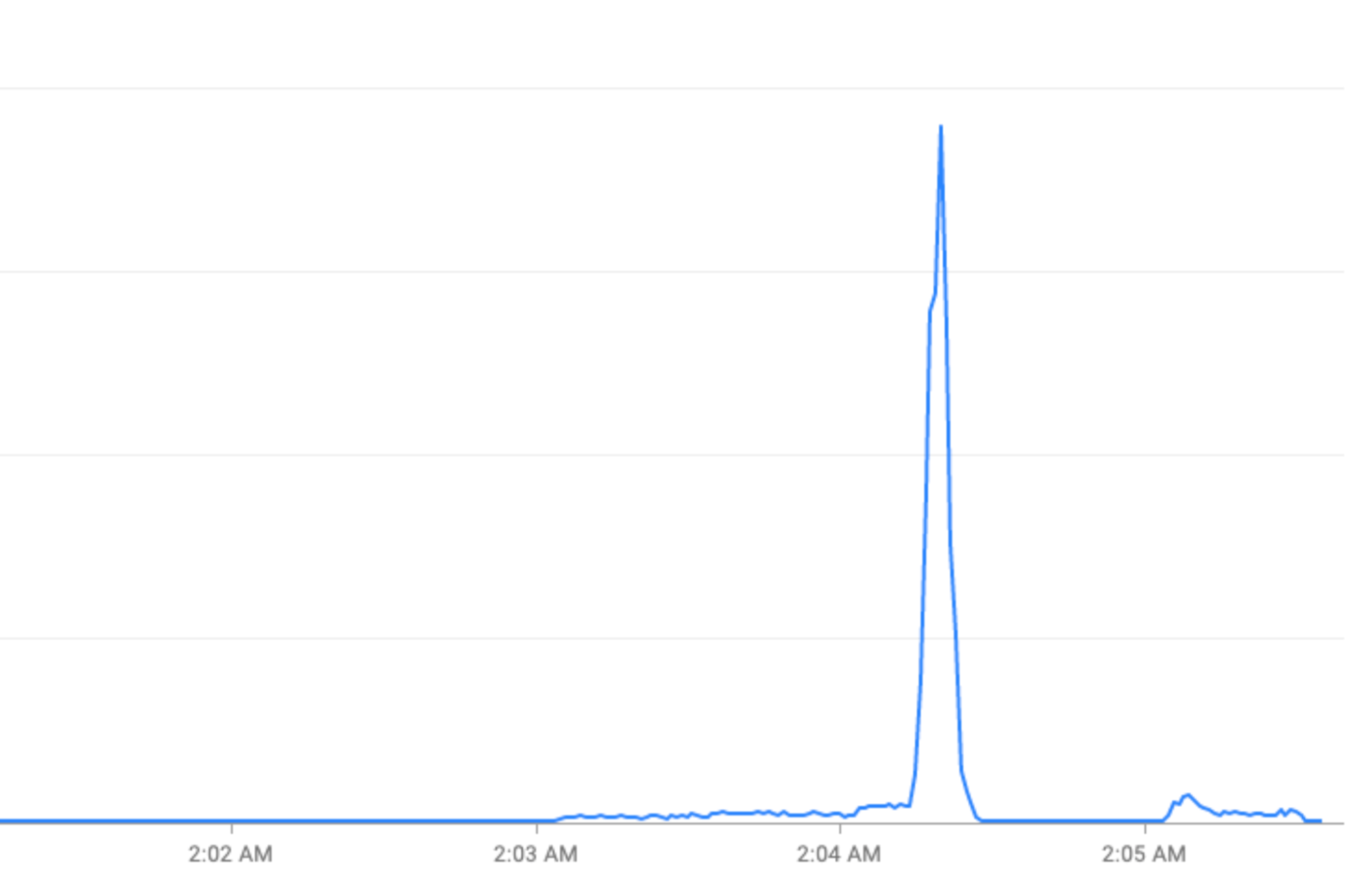
กิจกรรมพิเศษ: การเข้าชมที่เพิ่มขึ้นอย่างรวดเร็วในช่วงวันหยุด (วันส่งท้ายปีเก่า) หรือกิจกรรมกีฬา (ฟุตบอลโลก FIFA)
แก้ไขการเข้าชมที่เพิ่มขึ้นอย่างรวดเร็วด้วยการ "ลดการเพิ่มขึ้น"
ส่วนนี้อธิบายกลยุทธ์ในการลดการเข้าชมที่เพิ่มขึ้นอย่างรวดเร็วเมื่อเป็นไปได้ ซึ่งเป็นกลยุทธ์ในการ "ลดการเพิ่มขึ้น"
ใช้ FCM เฉพาะในกรณีการใช้งานที่เหมาะสม
มีกรณีการใช้งานบางกรณีที่ไม่จำเป็นหรือเหมาะสมที่จะใช้ FCM ในการส่งการแจ้งเตือน
ตัวอย่างเช่น สำหรับการแจ้งเตือนกิจกรรมในปฏิทิน คุณสามารถกำหนดเวลาให้แอปแสดงการแจ้งเตือนในเครื่องตามเวลาที่เหมาะสมแทนที่จะส่งจากเซิร์ฟเวอร์แอป จำกัดข้อความ FCM ให้ใช้สำหรับการซิงค์ปฏิทินเท่านั้น
หลีกเลี่ยงการเข้าชมที่เพิ่มขึ้นอย่างรวดเร็ว
รูปแบบที่ไม่แนะนำในการปรับขนาดคือการส่งการแจ้งเตือน FCM ให้เร็วที่สุดเท่าที่ระบบจะอนุญาตแทนที่จะใช้การจำกัดการส่งคำขอจากฝั่งเซิร์ฟเวอร์ โปรดพิจารณาสิ่งต่อไปนี้
- ลูกค้าทั้งหมดของคุณจำเป็นต้องได้รับการแจ้งเตือนเดียวกันภายในกรอบเวลา 1 นาทีหรือไม่ เช่น กรอบเวลาการส่ง 5 นาทีจะยังคงตอบสนองความต้องการทางธุรกิจของคุณได้หรือไม่
- คุณแบ่งกลุ่มลูกค้าตามลำดับความสำคัญเพื่อลดการเข้าชมที่เพิ่มขึ้นอย่างรวดเร็วได้หรือไม่
- คุณกำหนดเวลาการแจ้งเตือนล่วงหน้าได้หรือไม่
เมื่อเป็นไปได้: หลีกเลี่ยงกลยุทธ์ที่ทำให้โควต้าการส่ง FCM หมดลงทันที แล้วทำซ้ำรูปแบบเดิมทันทีที่บัคเก็ตโทเค็นเติม รูปแบบการเข้าถึงนี้ทำให้เกิดปัญหาการปรับสมดุลโหลดสำหรับ FCM และระบบที่ขึ้นอยู่กับ FCM เพิ่มการเข้าชมอย่างค่อยเป็นค่อยไปมากที่สุดเท่าที่จะทำได้ อย่างน้อยที่สุด ให้เพิ่มการเข้าชมจาก 0 เป็น RPS สูงสุดภายในกรอบเวลา 60 วินาที ควรใช้กรอบเวลาที่ยาวขึ้นสำหรับ RPS ที่สูงขึ้น
หลีกเลี่ยงการเข้าชม "เมื่อขึ้นชั่วโมงใหม่"
เมื่อเป็นไปได้: หลีกเลี่ยงการส่งข้อความภายในกรอบเวลา 2 นาทีของแต่ละช่วงเวลา :00, :15, :30 และ :45
ใช้การจำกัดการส่งคำขอจากฝั่งเซิร์ฟเวอร์
ใช้การจำกัดการส่งคำขอจากฝั่งเซิร์ฟเวอร์เพื่อตรวจสอบและจัดการการไหลของการเข้าชมไปยัง FCM
การจัดการการลองส่งคำขออีกครั้ง
แม้ว่า FCM จะพยายามให้บริการที่มีความพร้อมใช้งานสูง แต่บางครั้งคำขออาจหมดเวลาหรือล้มเหลว แม้ว่าเหตุผลจะแตกต่างกันไป แต่แนวทางปฏิบัติแนะนำต่อไปนี้จะเพิ่มประสิทธิภาพลักษณะการทำงานของการลองส่งคำขออีกครั้งเพื่อส่งข้อความให้เร็วที่สุดเท่าที่จะทำได้ พร้อมทั้งลดผลกระทบต่อการจราจรติดขัด
หมดเวลา
กำหนดระยะหมดเวลาอย่างน้อย 10 วินาทีสำหรับคำขอส่งก่อนที่จะลองส่งคำขออีกครั้ง การเรียกกระบวนการระยะไกลภายในส่วนใหญ่ของ FCM ใช้ระยะหมดเวลา 10 วินาที
ข้อผิดพลาด
- สำหรับข้อผิดพลาด 400, 401, 403, 404: ยกเลิกและไม่ลองส่งคำขออีกครั้ง
- สำหรับข้อผิดพลาด 429: ลองส่งคำขออีกครั้งหลังจากรอระยะเวลาที่กำหนดไว้ในส่วนหัว retry-after หากไม่ได้ตั้งค่าส่วนหัว retry-after ให้ใช้ค่าเริ่มต้นเป็น 60 วินาที
- สำหรับข้อผิดพลาด 500: ลองส่งคำขออีกครั้งโดยใช้ Exponential Backoff
Exponential Backoff
หากต้องการหลีกเลี่ยงการขยายการลองส่งคำขออีกครั้ง ให้ใช้ Exponential Backoff พร้อม Jittering สำหรับการลองส่งคำขออีกครั้ง ตัวอย่างเช่น Firebase Admin SDK ใช้ Exponential Backoff
การตั้งค่าที่แนะนำเพิ่มเติมมีดังนี้
- ช่วงเวลาขั้นต่ำ: ไม่ลองส่งคำขอที่ล้มเหลวอีกครั้งทันทีด้วย FCM รออย่างน้อย 10 วินาทีก่อนที่จะลองส่งคำขอที่ล้มเหลวอีกครั้ง
- ช่วงเวลาสูงสุด: กำหนดช่วงเวลาสูงสุดสำหรับการยกเลิกคำขอที่ไม่ทันเวลาอีกต่อไปแทนที่จะลองส่งคำขออีกครั้งอย่างไม่มีกำหนด
หากระบบลองส่งคำขออีกครั้งอย่างต่อเนื่องโดยใช้ Exponential Backoff และคำขอยังคงล้มเหลวหลังจากผ่านไป 60 นาที แสดงว่าคำขอนั้นถูกจัดหมวดหมู่ผิดว่าเป็นข้อผิดพลาดที่ลองส่งคำขออีกครั้งได้ หรือ FCM กำลังหยุดทำงานซึ่งการลองส่งคำขออีกครั้งอาจทำให้สถานการณ์แย่ลงโดยไม่ตั้งใจ
สร้างแผนการเปิดตัวและแผนการย้อนกลับ รวมถึงทำการเปลี่ยนแปลงอย่างค่อยเป็นค่อยไป
เมื่อทำการเปลี่ยนแปลงการเข้าชมขนาดใหญ่ เช่น การเพิ่มการเข้าชมไปยัง FCM หรือการย้ายการเข้าชมระหว่างภูมิภาคหรือเครือข่าย การออกแบบแผนการเปิดตัว/แผนการย้อนกลับและการทำการเปลี่ยนแปลงอย่างค่อยเป็นค่อยไปจะช่วยปกป้องผู้ใช้ บริการ และ FCM
- แผนการเปิดตัวจะช่วยให้ผู้มีส่วนได้ส่วนเสียเข้าใจตรงกัน ในบางสถานการณ์ (กล่าวถึงด้านล่าง) คุณอาจต้องการแชร์แผนการเปิดตัวกับทีม FCM ล่วงหน้าเพื่อหลีกเลี่ยงความประหลาดใจ
- แผนการย้อนกลับช่วยให้คุณพิจารณาสถานการณ์ที่ไม่คาดคิดและเตรียมกลไกในการกู้คืนจากความล้มเหลวที่ไม่คาดคิดได้อย่างรวดเร็วและปลอดภัย
- การทำการเปลี่ยนแปลงอย่างค่อยเป็นค่อยไปมี 2 ด้าน ได้แก่
- การเพิ่มขึ้นแบบ "ทีละขั้น": ขั้นตอนควรเป็น 1% -> 5% -> 10% -> 25% -> 50% -> 75% -> 100% หรือละเอียดกว่านั้น "ทดสอบ" (สังเกตลักษณะการทำงานของระบบภายใต้โหลด) แต่ละขั้นตอนเป็นเวลา 1 วันถึง 1 สัปดาห์ ซึ่งจะช่วยให้คุณพบปัญหาที่อาจเกิดขึ้นก่อนที่จะ "เพิ่ม" ขั้นตอนถัดไป
- การเพิ่มการเข้าชมอย่างค่อยเป็นค่อยไป: เมื่อทำตาม "ขั้นตอน" แต่ละขั้นตอนเพื่อเพิ่มการเข้าชม ให้กระจายการเข้าชมอย่างสม่ำเสมอในช่วงเวลาอย่างน้อย 1 ชั่วโมง ซึ่งจะช่วยให้โครงสร้างพื้นฐานการปรับสมดุลโหลดของ FCM ปรับขนาดการเข้าชมใหม่ได้อย่างเหมาะสม พร้อมทั้งลดโอกาสที่จะเกิดฮอตสปอตและการจราจรติดขัด
ต่อไปนี้เป็นสถานการณ์สมมติสำหรับการย้ายข้อมูล 500,000 RPS ทั่วโลกจาก FCM Legacy HTTP API ไปยัง FCM HTTP v1 API
| สัปดาห์ | ขั้นตอน | กลยุทธ์การเพิ่มขึ้นอย่างค่อยเป็นค่อยไป |
|---|---|---|
| 0 | การเพิ่มขึ้น 1% | เพิ่มการเข้าชมจาก 0 เป็น 5,000 RPS ไปยัง FCM HTTP v1 อย่างราบรื่นภายใน 1 ชั่วโมง |
| 1 | การเพิ่มขึ้น 5% | เพิ่มการเข้าชมจาก 5,000 เป็น 25,000 RPS อย่างราบรื่นภายใน 2 ชั่วโมง |
| 2 | การเพิ่มขึ้น 10% | เพิ่มการเข้าชมจาก 25,000 เป็น 50,000 RPS อย่างราบรื่นภายใน 2 ชั่วโมง |
| 3 | การเพิ่มขึ้น 25% | เพิ่มการเข้าชมจาก 50,000 เป็น 125,000 RPS ภายใน 3 ชั่วโมง |
| 4 | การเพิ่มขึ้น 50% | เพิ่มการเข้าชมจาก 125,000 เป็น 250,000 RPS ภายใน 6 ชั่วโมง |
| 5 | การเพิ่มขึ้น 75% | เพิ่มการเข้าชมจาก 250,000 เป็น 375,000 RPS ภายใน 6 ชั่วโมง |
| 6 | การเพิ่มขึ้น 100% | เพิ่มการเข้าชมจาก 375,000 เป็น 500,000 RPS ภายใน 6 ชั่วโมง |
แผนการย้อนกลับสมมติ
- หากเวลาในการตอบสนองเปอร์เซ็นไทล์ที่ 95 เพิ่มขึ้นเป็นมากกว่า 500 มิลลิวินาที หรือหากอัตราข้อผิดพลาดเกิน 1% เป็นเวลานานกว่า 1 ชั่วโมงในขั้นตอนใดก็ตาม ให้ใช้การกำหนดค่าแบบไดนามิกเพื่อย้อนกลับไปยังขั้นตอนก่อนหน้าทันที
- ดำเนินการย้อนกลับไปยังขั้นตอนก่อนหน้าต่อไปจนกว่าเวลาในการตอบสนองและอัตราข้อผิดพลาดจะกลับสู่ระดับปกติ
กรณีที่ควรติดต่อ FCM
ติดต่อ FCM ผ่าน ทีมสนับสนุน Firebase หากมีกรณีใดกรณีหนึ่งต่อไปนี้
- โควต้าเริ่มต้นไม่ตรงกับกรณีการใช้งานของคุณอีกต่อไป
- คุณกำลังเปลี่ยนรูปแบบการส่งภายในกรอบเวลา 3 เดือนในระดับ 100,000 RPS ทั่วโลกหรือ 30,000 RPS ในทวีป