
Read this document to make informed decisions on architecting your applications for high performance and reliability. This document includes advanced Cloud Firestore topics. If you're just starting out with Cloud Firestore, see the quickstart guide instead.
Cloud Firestore is a flexible, scalable database for mobile device, web, and server development from Firebase and Google Cloud. It's very easy to get started with Cloud Firestore and write rich and powerful applications.
To make sure that your applications continue to perform well as your database size and traffic increase, it helps to understand the mechanics of reads and writes in the Cloud Firestore backend. You must also understand the interaction of your read and writes with the storage layer and the underlying constraints that may affect performance.
See the following sections for best practices before architecting your application.
Understand the high level components
The following diagram shows the high level components involved in a Cloud Firestore API request.
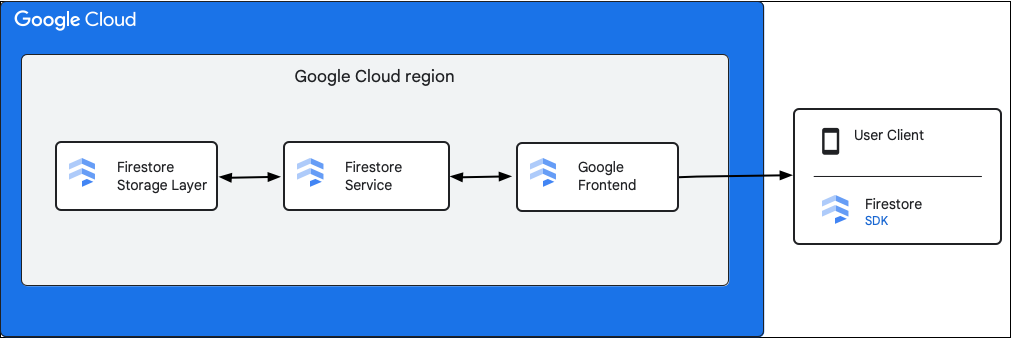
Cloud Firestore SDK and client libraries
Cloud Firestore supports SDKs and client libraries for different platforms. While an app can make direct HTTP and RPC calls to the Cloud Firestore API, the client libraries provide a layer of abstraction to simplify API usage and implement best practices. They may also provide additional features such as offline access, caches, and so on.
Google Front End (GFE)
This is an infrastructure service common to all Google cloud services. The GFE accepts incoming requests and forwards them to the relevant Google service (Cloud Firestore service in this context). It also provides other important functionalities, including protection against Denial of Service attacks.
Cloud Firestore service
The Cloud Firestore service performs checks on the API request, which includes authentication, authorization, quota checks, and security rules, and also manages transactions. This Cloud Firestore service includes a storage client that interacts with the storage layer for the data reads and writes.
Cloud Firestore storage layer
The Cloud Firestore storage layer is responsible for storing both the data and metadata, and the associated database features provided by Cloud Firestore. The following sections describe how data is organized in the Cloud Firestore storage layer and how the system scales. Learning about how data is organized can help you design a scalable data model and better understand the best practices in Cloud Firestore.
Key Ranges and Splits
Cloud Firestore is a NoSQL, document-oriented database. You store data in documents, which are organized in hierarchies of collections. The collection hierarchy and document ID are translated to a single key for each document. Documents are logically stored and ordered lexicographically by this single key. We use the term key range to refer to a lexicographically contiguous range of keys.
A typical Cloud Firestore database is too large to fit on a single physical machine. There are also scenarios where the workload on the data is too heavy for one machine to handle. To handle large workloads, Cloud Firestore partitions the data into separate pieces that can be stored on and served from multiple machines or storage servers. These partitions are made on the database tables in blocks of key ranges called splits.
Synchronous Replication
It is important to note that the database is always being replicated automatically and synchronously. The splits of data have replicas in different zones to keep them available even when a zone becomes inaccessible. Consistent replication to the different copies of the split is managed by the Paxos algorithm for consensus. One replica of each split is elected to act as the Paxos leader, which is responsible for handling writes to that split. The synchronous replication gives you the ability to always be able to read the latest version of data from Cloud Firestore.
The overall result of this is a scalable and highly available system that provides low latencies for both reads and writes, irrespective of heavy workloads and at very large scale.
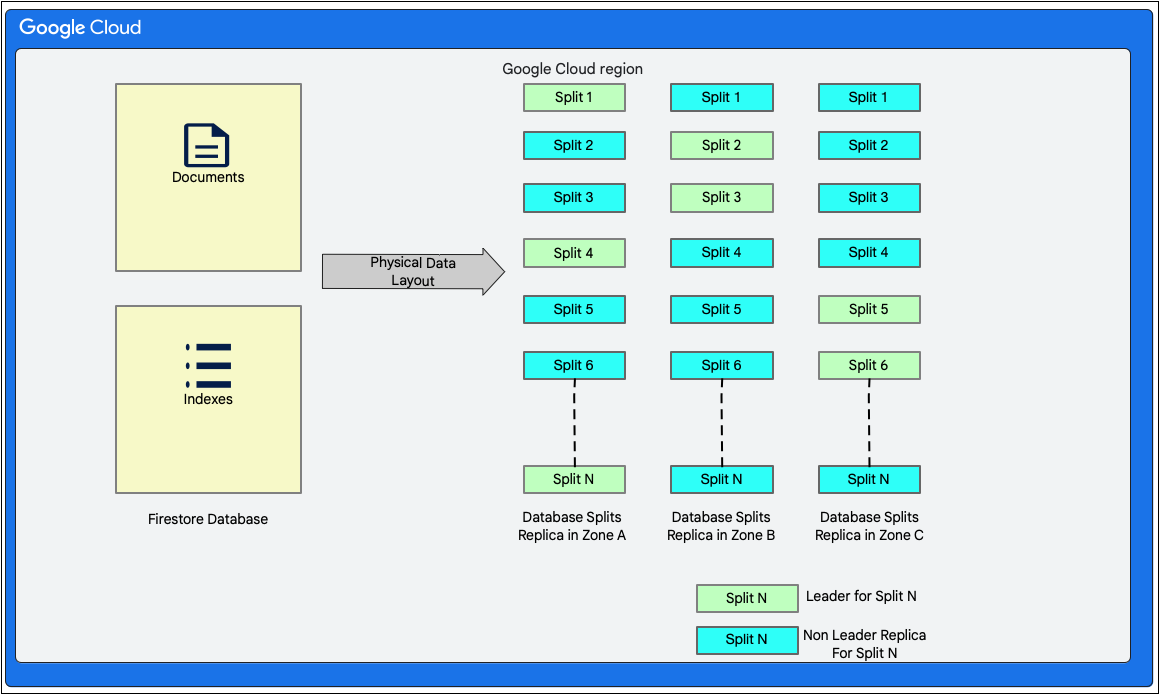
Data layout
Cloud Firestore is a schemaless document database. However, internally it lays out the data primarily in two relational database-style tables in its storage layer as follows:
- Documents table: Documents are stored in this table.
- Indexes table: Index entries that make it possible to get results efficiently and sorted by index value are stored in this table.
The following diagram shows how the tables for a Cloud Firestore database might look like with the splits. The splits are replicated in three different zones and each split has an assigned Paxos leader.
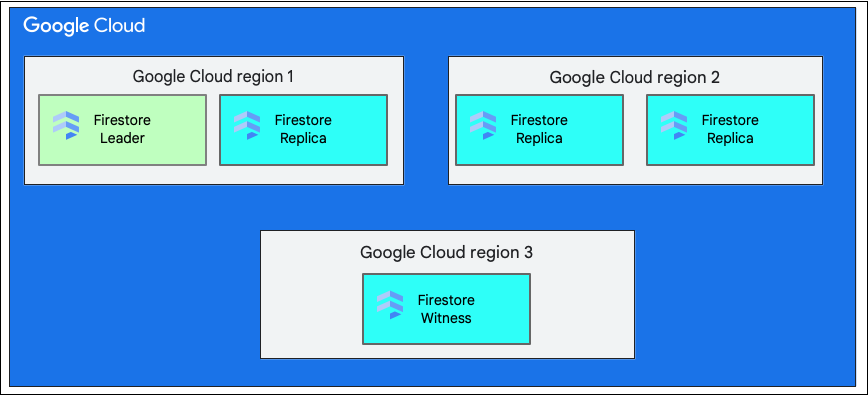
Single Region versus Multi-Region
When you create a database, you must select a region or multi-region.
A single regional location is a specific geographic location, like us-west1. The splits of data of a Cloud Firestore database have replicas in different zones within the selected region, as explained earlier.
A multi-region location consists of a defined set of regions where replicas of the database are stored. In a multi-region deployment of Cloud Firestore, two of the regions have full replicas of the entire data in the database. A third region has a witness replica that does not maintain a full set of data, but participates in replication. By replicating the data between multiple regions, data is available to be written and read even with the loss of an entire region.
For more information about the locations of a region, see Cloud Firestore locations.
Understand life of a write in Cloud Firestore
A Cloud Firestore client can write data by creating, updating, or deleting a single document. A write to a single document requires updating both the document and its associated index entries atomically in the storage layer. Cloud Firestore also supports atomic operations consisting of multiple reads and/or writes to one or more documents.
For all kinds of writes, Cloud Firestore provides the ACID properties (atomicity, consistency, isolation, and durability) of relational databases. Cloud Firestore also provides serializability, which means that all transactions appear as if executed in a serial order.
High-level steps in a write transaction
When the Cloud Firestore client issues a write or commits a transaction, using any of the methods mentioned earlier, internally this is executed as a database read-write transaction in the storage layer. The transaction enables Cloud Firestore to provide the ACID properties mentioned earlier.
As the first step of a transaction, Cloud Firestore reads the existing document, and determines the mutations to be made to the data in the Documents table.
This also includes making necessary updates to the Indexes table as follows:
- Fields that are being added to the documents need corresponding inserts in the Indexes table.
- Fields that are being removed from the documents need corresponding deletes in the Indexes table.
- Fields that are being modified in the documents, need both deletes (for old values) and inserts (for new values) in the Indexes table.
To calculate the mutations mentioned earlier, Cloud Firestore reads the indexing configuration for the project. The indexing configuration stores information about the indexes for a project. Cloud Firestore uses two types of indexes: single-field and composite. For a detailed understanding of the indexes created in Cloud Firestore, see Index types in Cloud Firestore.
Once the mutations are calculated, Cloud Firestore collects them inside a transaction and then commits it.
Understand a write transaction in the storage layer
As discussed earlier, a write in Cloud Firestore involves a read-write transaction in the storage layer. Depending on the layout of data, a write might involve one or more splits as seen in the data layout.
In the following diagram, the Cloud Firestore database has eight splits (marked 1-8) hosted on three different storage servers in a single zone, and each split is replicated in 3(or more) different zones. Each split has a Paxos leader, which might be in a different zone for different splits.
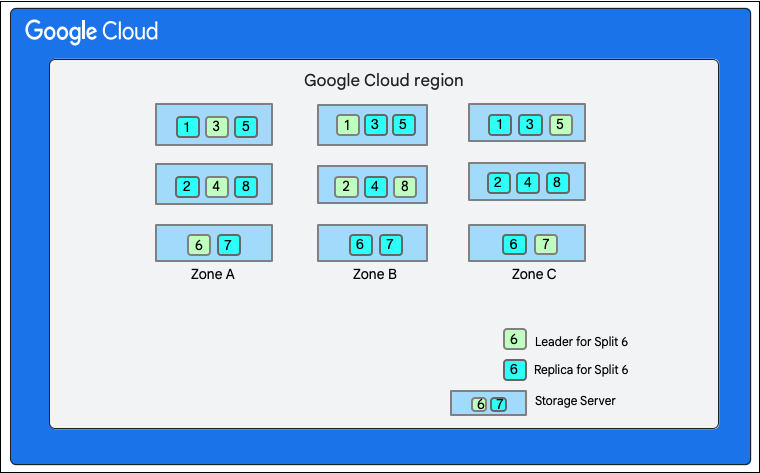 Cloud Firestore database split">
Cloud Firestore database split">
Consider a Cloud Firestore database that has the Restaurants collection as follows:
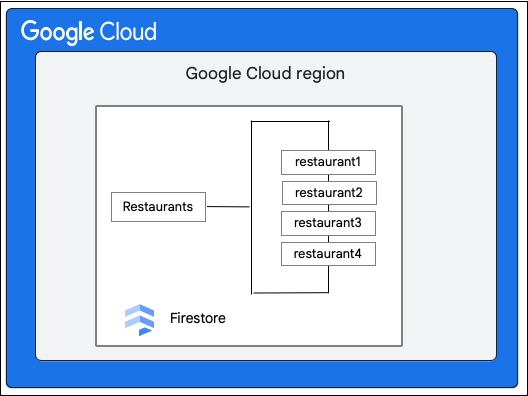
The Cloud Firestore client requests the following change to a document in the Restaurant collection by updating the value of the priceCategory field.
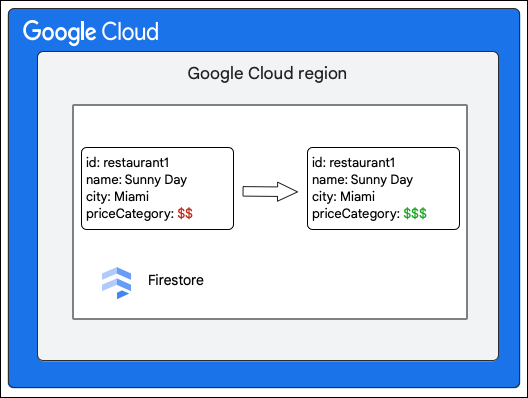
The following high-level steps describe what happens as part of the write:
- Create a read-write transaction.
- Read the
restaurant1document in theRestaurantscollection from the Documents table from the storage layer. - Read the indexes for the document from the Indexes table.
- Compute the mutations to be made to the data. In this case, there are five mutations:
- M1: Update the row for
restaurant1in the Documents table to reflect the change in value of thepriceCategoryfield. - M2 and M3: Delete the rows for the old value of
priceCategoryin the Indexes table for descending and ascending indexes. - M4 and M5: Insert the rows for the new value of
priceCategoryin the Indexes table for descending and ascending indexes.
- M1: Update the row for
- Commit these mutations.
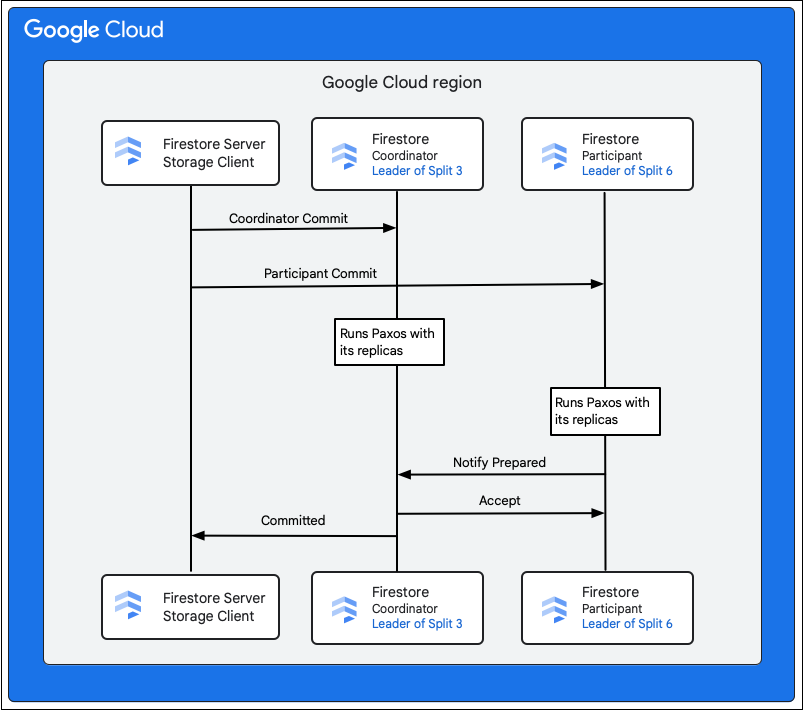
The storage client in the Cloud Firestore service looks up the splits that owns the keys of the rows to be changed. Let’s consider a case where Split 3 serves M1, and Split 6 serves M2-M5. There is a distributed transaction, involving all these splits as participants. The participant splits may also include any other split from which data was read earlier as part of the read-write transaction.
The following steps describe what happens as part of the commit:
- The storage client issues a commit. The commit contains the mutations M1-M5.
- Splits 3 and 6 are the participants in this transaction. One of the participants is chosen as the coordinator, such as Split 3. The job of the coordinator is to make sure the transaction either commits or aborts atomically across all participants.
- The leader replicas of these splits are responsible for work done by the participants and coordinators.
- Each participant and coordinator runs a Paxos algorithm with their respective replicas.
- The leader runs a Paxos algorithm with the replicas. Quorum is achieved if most of the replicas reply with an
ok to commitresponse to the leader. - Each participant then notifies the coordinator when they are prepared (first phase of two-phase commit). If any participant cannot commit the transaction, the whole transaction
aborts.
- The leader runs a Paxos algorithm with the replicas. Quorum is achieved if most of the replicas reply with an
- Once the coordinator knows all participants, including itself, are prepared, it communicates the
accepttransaction outcome to all the participants (second phase of two-phase commit). In this phase, each participant records the commit decision to stable storage and the transaction is committed. - The coordinator responds to the storage client in Cloud Firestore that the transaction has been committed. In parallel, the coordinator and all the participants apply the mutations to the data.
When the Cloud Firestore database is small, it may happen that a single split owns all the keys in the mutations M1-M5. In such a case, there is only one participant in the transaction and the two-phase commit mentioned earlier is not required, thus making the writes faster.
Writes in multi-region
In a multi-region deployment, the spread of replicas across regions increases availability, but comes with a performance cost. The communication between replicas in different regions takes longer round trip times. Hence, the baseline latency for Cloud Firestore operations is slightly more compared to single region deployments.
We configure the replicas in a way that leadership for splits always stays in the primary region. The primary region is the one from which traffic is incoming to the Cloud Firestore server. This decision of leadership reduces the round-trip delay in communication between the storage client in Cloud Firestore and the replica leader (or coordinator for multi-split transactions).
Each write in Cloud Firestore also involves some interaction with the real-time engine in Cloud Firestore. For more information about real-time queries, see Understand real-time queries at scale.
Understand the life of a read in Cloud Firestore
This section delves into standalone, non-realtime reads in Cloud Firestore. Internally, the Cloud Firestore server handles most of these queries in two major stages:
- A single range scan over the Indexes table
- Point lookups in the Documents table based on the result of the earlier scan
The data reads from the storage layer are internally done by using a database transaction to ensure consistent reads. However, unlike the transactions used for writes, these transactions do not take locks. Instead, they work by choosing a timestamp, then executing all reads at that timestamp. Since they do not acquire locks, they do not block concurrent read-write transactions. To execute this transaction, the storage client in Cloud Firestore specifies a timestamp bound, which tells the storage layer how to choose a read timestamp. The type of timestamp bound chosen by the storage client in Cloud Firestore is determined by the read options for the Read request.
Understand a read transaction in the storage layer
This section describes the types of reads and how they are processed in the storage layer in Cloud Firestore.
Strong reads
By default, Cloud Firestore reads are strongly consistent. This strong consistency means that a Cloud Firestore read returns the latest version of the data that reflects all writes that have been committed up until the start of the read.
Single Split read
The storage client in Cloud Firestore looks up the splits that own the keys of the rows to be read. Let’s assume that it needs to do a read from Split 3 from the earlier section. The client sends the read request to the nearest replica to reduce round trip latency.
At this point, the following cases might happen depending on the chosen replica:
- Read request goes to a leader replica (Zone A).
- As the leader is always up-to-date, the read can proceed directly.
- Read request goes to a non-leader replica (such as, Zone B)
- Split 3 may know by its internal state that it has enough information to serve the read and the split does so.
- Split 3 is unsure if it has seen the latest data. It sends a message to the leader to ask for the timestamp of the last transaction it needs to apply to serve the read. Once that transaction is applied, the read can proceed.
Cloud Firestore then returns the response to its client.
Multi-split read
In the situation where the reads have to be done from multiple splits, the same mechanism happens across all the splits. Once the data has been returned from all the splits, the storage client in Cloud Firestore combines the results. Cloud Firestore then responds to its client with this data.
Stale reads
Strong reads are the default mode in Cloud Firestore. However, it comes at a cost of potential higher latency due to the communication that may be required with the leader. Often your Cloud Firestore application doesn’t need to read the latest version of the data and the functionality works well with data that may be a few seconds stale.
In such a case, the client may opt to receive stale reads by using the read_time read options. In this case, reads are done as the data was at read_time, and the closest replica is highly likely to already have verified it has data at the specified read_time.
For noticeably better performance, 15 seconds is a reasonable staleness value. Even for stale reads, rows yielded are consistent with each other.
Avoid hotspots
The splits in Cloud Firestore are automatically broken into smaller pieces to distribute the work of serving traffic to more storage servers when needed or when the key space expands. Splits created to handle excess traffic are retained for around ~24 hours even if the traffic goes away. So if there are recurring traffic spikes, the splits are maintained and more splits are introduced whenever required. These mechanisms help Cloud Firestore databases to autoscale under increasing traffic load or database size. However, there are some limitations to be aware of as explained below.
Splitting storage and load takes time, and ramping up traffic too fast may cause high latency or deadline exceeded errors, commonly referred to as hotspots, while the service adjusts. The best practice is to distribute operations across the key range, while ramping up traffic on a collection in a database with 500 operations per second. After this gradual ramp up, increase the traffic by up to 50% every five minutes. This process is called the 500/50/5 rule and positions the database to optimally scale to meet your workload.
Though splits are created automatically with increasing load, Cloud Firestore can split a key range only until it's serving a single document using a dedicated set of replicated storage servers. As a result, high and sustained volumes of concurrent operations on a single document may lead to a hotspot on that document. If you encounter sustained high latencies on a single document, you should consider modifying your data model to split or replicate the data across multiple documents.
Contention errors happen when multiple operations try to read and/or write the same document simultaneously.
Another special case of hotspotting happens when a sequentially increasing/decreasing key is used as the document ID in Cloud Firestore, and there is a considerably high number of operations per second. Creating more splits doesn’t help here since the surge of traffic simply moves to the newly created split. Since Cloud Firestore automatically indexes all fields in the document by default, such moving hotspots may also be created on the index space for a document field that contains a sequentially increasing/decreasing value like a timestamp.
Note that by following the practices outlined above, Cloud Firestore can scale to serve arbitrarily large workloads without you having to adjust any configuration.
Troubleshooting
Cloud Firestore provides the Key Visualizer as a diagnostic tool designed to analyze usage patterns and troubleshoot hotspotting issues.
What's Next
- Read about more best practices
- Learn about real-time queries at scale