
Ознакомьтесь с этим документом, чтобы принимать обоснованные решения по проектированию архитектуры ваших приложений для обеспечения высокой производительности и надежности. Этот документ содержит расширенные темы, касающиеся Cloud Firestore . Если вы только начинаете работать с Cloud Firestore , обратитесь к краткому руководству .
Cloud Firestore — это гибкая, масштабируемая база данных для разработки мобильных приложений, веб-сайтов и серверов от Firebase и Google Cloud . Начать работу с Cloud Firestore и создавать многофункциональные и мощные приложения очень просто.
Чтобы ваши приложения продолжали эффективно работать по мере увеличения размера базы данных и трафика, полезно понимать механику операций чтения и записи в бэкэнде Cloud Firestore . Также необходимо понимать взаимодействие операций чтения и записи с уровнем хранения и основные ограничения, которые могут влиять на производительность.
Перед разработкой архитектуры приложения ознакомьтесь с рекомендациями в следующих разделах.
Разберитесь в компонентах высокого уровня.
На следующей диаграмме показаны основные компоненты, участвующие в запросе к API Cloud Firestore .
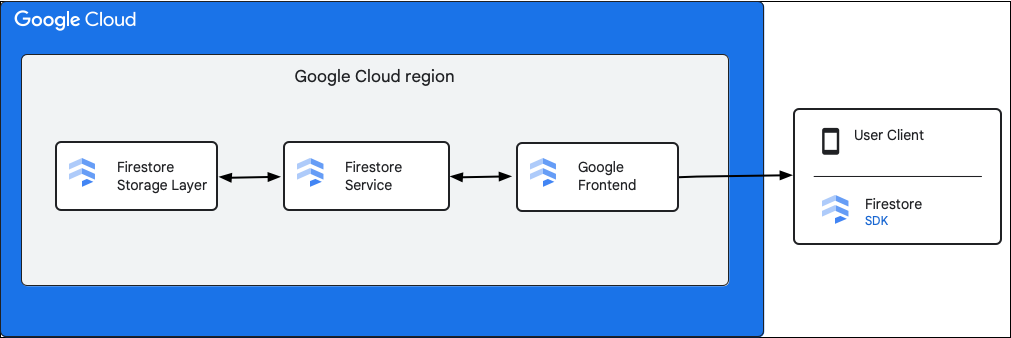
SDK и клиентские библиотеки Cloud Firestore
Cloud Firestore поддерживает SDK и клиентские библиотеки для различных платформ. Хотя приложение может напрямую обращаться к API Cloud Firestore по протоколам HTTP и RPC, клиентские библиотеки обеспечивают уровень абстракции, упрощающий использование API и позволяющий внедрять лучшие практики. Они также могут предоставлять дополнительные функции, такие как автономный доступ, кэширование и так далее.
Google Front End (GFE)
Это инфраструктурный сервис, общий для всех облачных сервисов Google. GFE принимает входящие запросы и перенаправляет их в соответствующий сервис Google (в данном контексте — в сервис Cloud Firestore ). Он также предоставляет другие важные функции, включая защиту от атак типа «отказ в обслуживании» (DoS).
Сервис Cloud Firestore
Сервис Cloud Firestore выполняет проверки API-запросов, включая аутентификацию, авторизацию, проверку квот и правила безопасности, а также управляет транзакциями. Этот сервис Cloud Firestore включает в себя клиент хранилища , который взаимодействует с уровнем хранилища для чтения и записи данных.
Уровень хранения Cloud Firestore
Уровень хранения Cloud Firestore отвечает за хранение как данных, так и метаданных, а также связанных с ними функций базы данных, предоставляемых Cloud Firestore . В следующих разделах описывается, как организованы данные на уровне хранения Cloud Firestore и как масштабируется система. Изучение организации данных поможет вам разработать масштабируемую модель данных и лучше понять лучшие практики работы с Cloud Firestore .
Ключевые диапазоны и разделения
Cloud Firestore — это NoSQL-база данных, ориентированная на документы. Данные хранятся в документах , которые организованы в иерархии коллекций . Иерархия коллекций и идентификатор документа преобразуются в единый ключ для каждого документа. Документы логически хранятся и упорядочиваются лексикографически по этому единственному ключу. Термин «диапазон ключей» используется для обозначения лексикографически непрерывного диапазона ключей.
Типичная база данных Cloud Firestore слишком велика, чтобы поместиться на одной физической машине. Также существуют сценарии, когда нагрузка на данные слишком велика для обработки одной машиной. Для обработки больших объемов данных Cloud Firestore разделяет данные на отдельные части, которые могут храниться и предоставляться с нескольких машин или серверов хранения . Эти разделы создаются в таблицах базы данных в виде блоков диапазонов ключей, называемых разбиениями.
Синхронная репликация
Важно отметить, что база данных всегда автоматически и синхронно реплицируется. Разделы данных имеют реплики в разных зонах , чтобы обеспечить их доступность даже в случае недоступности какой-либо зоны. Согласованная репликация на разные копии раздела управляется алгоритмом консенсуса Paxos . Одна реплика каждого раздела выбирается в качестве лидера Paxos, который отвечает за обработку операций записи в этот раздел. Синхронная репликация позволяет всегда иметь возможность читать самую последнюю версию данных из Cloud Firestore .
В результате получается масштабируемая и высокодоступная система, обеспечивающая низкую задержку как при чтении, так и при записи, независимо от высокой нагрузки и в очень больших масштабах.
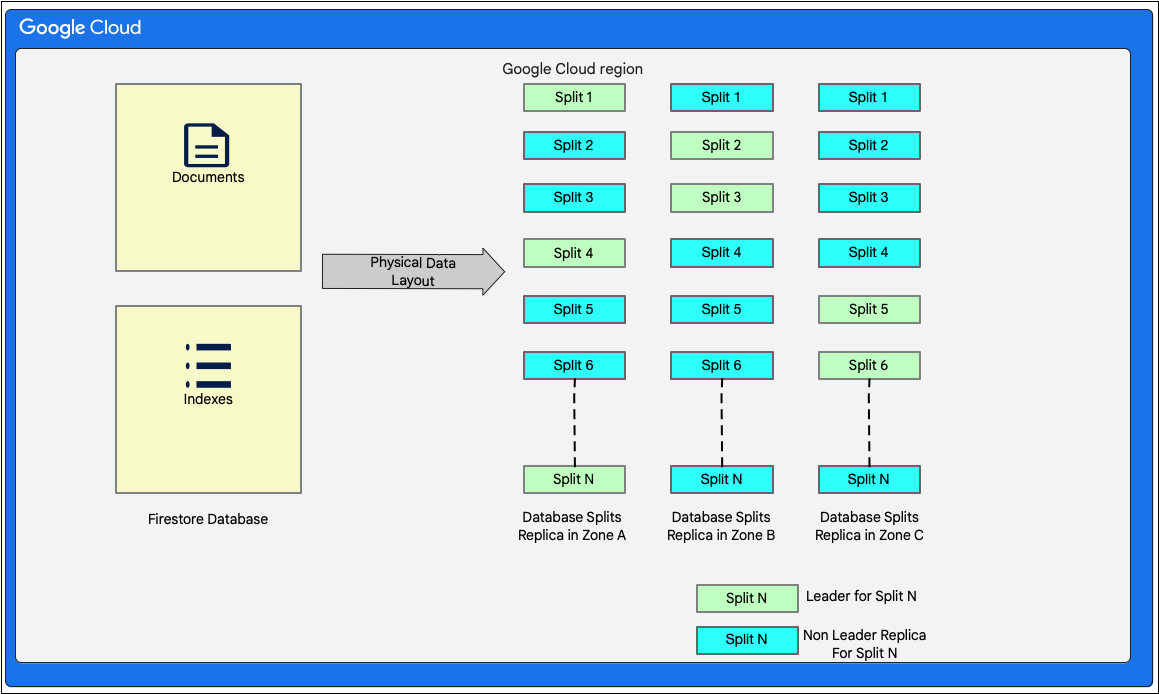
Структура данных
Cloud Firestore — это документоориентированная база данных без схемы. Однако внутри она хранит данные преимущественно в двух таблицах, построенных по принципу реляционных баз данных, на уровне хранилища следующим образом:
- Таблица «Документы» : В этой таблице хранятся документы.
- Таблица индексов : В этой таблице хранятся записи индексов, позволяющие эффективно получать результаты, отсортированные по значению индекса.
На следующей диаграмме показано, как могут выглядеть таблицы базы данных Cloud Firestore с учетом разделения на зоны. Разделения реплицируются в трех разных зонах, и каждому разделению назначен лидер Paxos.
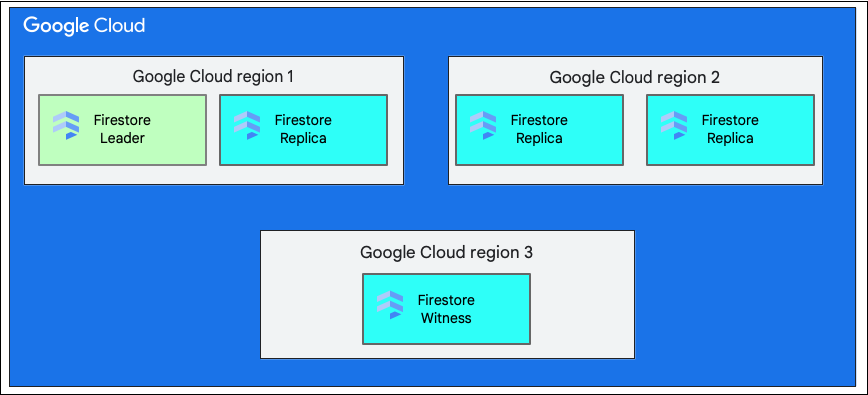
Один регион против нескольких регионов
При создании базы данных необходимо выбрать регион или несколько регионов .
Отдельный региональный локационный узел — это конкретное географическое местоположение, например, us-west1 . Разделение данных в базе данных Cloud Firestore имеет реплики в разных зонах внутри выбранного региона, как объяснялось ранее.
Многорегиональное размещение представляет собой определенный набор регионов, где хранятся реплики базы данных. В многорегиональной конфигурации Cloud Firestore два региона содержат полные реплики всех данных базы данных. Третий регион имеет реплику-свидетель , которая не хранит полный набор данных, но участвует в репликации. Благодаря репликации данных между несколькими регионами, данные остаются доступными для записи и чтения даже при потере данных в одном из регионов.
Для получения более подробной информации о местоположении региона см. раздел «Местоположение Cloud Firestore .
Понимание жизненного цикла операции записи в Cloud Firestore
Клиент Cloud Firestore может записывать данные, создавая, обновляя или удаляя один документ. Запись в один документ требует атомарного обновления как самого документа, так и связанных с ним записей индекса на уровне хранения. Cloud Firestore также поддерживает атомарные операции, состоящие из нескольких операций чтения и/или записи в один или несколько документов.
Для всех типов операций записи Cloud Firestore обеспечивает свойства ACID (атомарность, согласованность, изоляция и надежность), характерные для реляционных баз данных. Cloud Firestore также обеспечивает сериализуемость , что означает, что все транзакции отображаются так, как если бы они выполнялись последовательно.
Основные этапы транзакции записи
Когда клиент Cloud Firestore выполняет операцию записи или подтверждает транзакцию, используя любой из упомянутых ранее методов, внутри системы это выполняется как транзакция чтения-записи в базе данных на уровне хранения. Эта транзакция позволяет Cloud Firestore обеспечивать свойства ACID, упомянутые ранее.
В качестве первого шага транзакции Cloud Firestore считывает существующий документ и определяет, какие изменения необходимо внести в данные в таблице Documents.
Это также включает в себя внесение необходимых изменений в таблицу Indexes следующим образом:
- Для полей, добавляемых в документы, необходимо выполнить соответствующие вставки в таблицу «Индексы».
- Для полей, удаляемых из документов, необходимо выполнить соответствующее удаление в таблице «Индексы».
- Для полей в документах, подвергающихся изменению, необходимо выполнить как удаление (для старых значений), так и вставку (для новых значений) в таблицу Indexes.
Для вычисления упомянутых ранее мутаций Cloud Firestore считывает конфигурацию индексирования для проекта. Конфигурация индексирования хранит информацию об индексах для проекта. Cloud Firestore использует два типа индексов: однопольные и составные. Для более подробного понимания индексов, создаваемых в Cloud Firestore , см. раздел «Типы индексов в Cloud Firestore .
После вычисления изменений Cloud Firestore собирает их в транзакцию, а затем фиксирует её.
Разберитесь в транзакции записи на уровне хранения данных.
Как обсуждалось ранее, операция записи в Cloud Firestore включает в себя транзакцию чтения-записи на уровне хранилища. В зависимости от структуры данных, запись может включать одно или несколько разделений, как показано на схеме структуры данных .
На следующей диаграмме база данных Cloud Firestore имеет восемь разделов (обозначенных цифрами 1-8), размещенных на трех разных серверах хранения в одной зоне, и каждый раздел реплицируется в 3 (или более) разных зонах. У каждого раздела есть лидер Paxos, который может находиться в разных зонах для разных разделов.
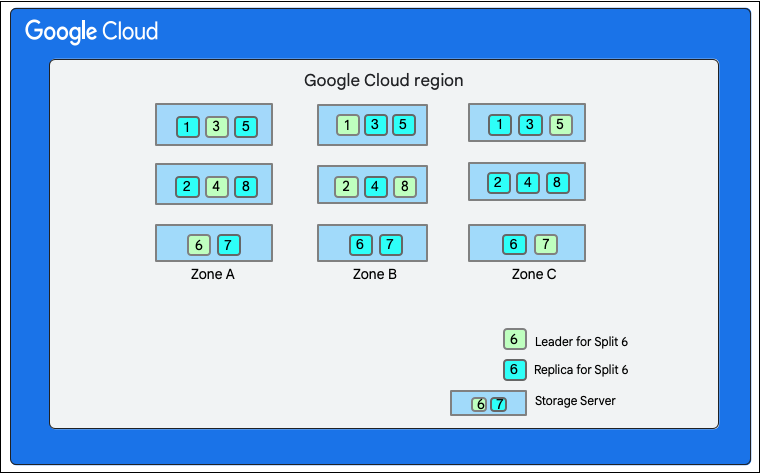 Разделение базы данных Cloud Firestore">
Разделение базы данных Cloud Firestore">
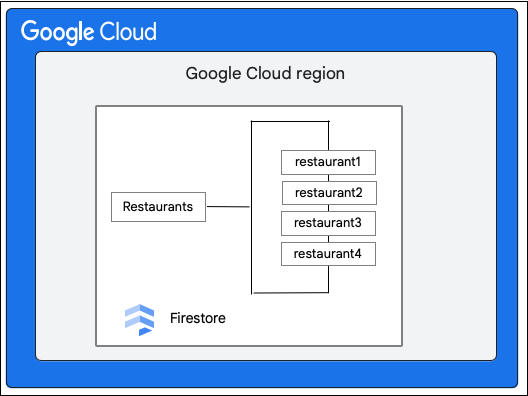
Рассмотрим базу данных Cloud Firestore , содержащую коллекцию Restaurants следующего вида:
Клиент Cloud Firestore запрашивает следующее изменение в документе из коллекции Restaurant , обновляя значение поля priceCategory .
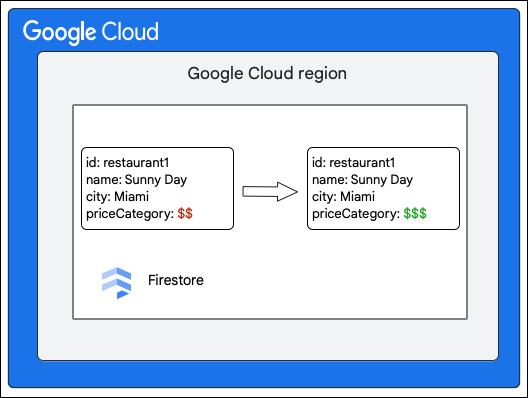
Следующие основные шаги описывают то, что происходит в процессе записи:
- Создайте транзакцию чтения и записи.
- Прочитайте документ
restaurant1из коллекцииRestaurantsиз таблицы Documents на уровне хранилища. - Прочитайте оглавление документа из таблицы «Оглавления» .
- Вычислите количество изменений, которые необходимо внести в данные. В данном случае имеется пять изменений:
- M1: Обновите строку для
restaurant1в таблице «Документы» , чтобы отразить изменение значения поляpriceCategory. - M2 и M3: Удалите строки со старым значением
priceCategoryв таблице Indexes для убывающих и возрастающих индексов. - M4 и M5: Вставьте строки с новым значением
priceCategoryв таблицу Indexes для убывающих и возрастающих индексов.
- M1: Обновите строку для
- Произведите эти мутации.
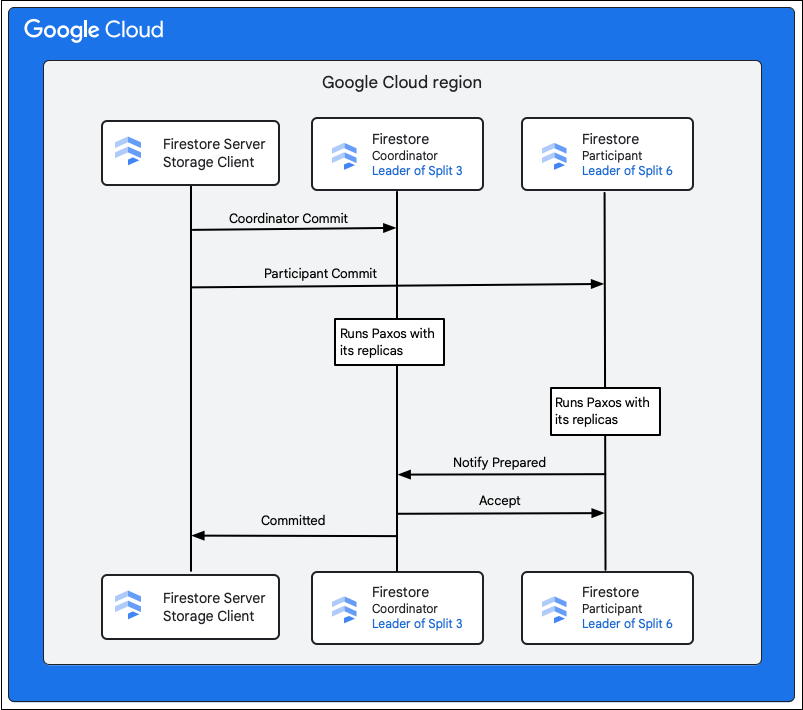
Клиент хранилища в сервисе Cloud Firestore ищет разделы, которым принадлежат ключи строк, подлежащих изменению. Рассмотрим случай, когда раздел 3 обслуживает M1, а раздел 6 — M2-M5. Происходит распределенная транзакция, в которой все эти разделы выступают в качестве участников . В число участвующих разделов могут также входить любые другие разделы, из которых данные были ранее прочитаны в рамках транзакции чтения-записи.
Следующие шаги описывают, что происходит в процессе фиксации изменений:
- Клиент хранилища отправляет команду commit. Команда commit содержит изменения M1-M5.
- В данной транзакции участвуют группы 3 и 6. Один из участников выбирается в качестве координатора , например, группа 3. Задача координатора — обеспечить атомарное завершение или прерывание транзакции всеми участниками.
- Руководители, выполняющие функции координаторов в этих группах, несут ответственность за работу, проделанную участниками и координаторами.
- Каждый участник и координатор запускает алгоритм Paxos со своими соответствующими репликами.
- Лидер запускает алгоритм Paxos с репликами. Кворум достигается, если большинство реплик отвечают лидеру подтверждением
ok to commit. - Затем каждый участник уведомляет координатора о своей готовности (первый этап двухэтапной фиксации). Если какой-либо участник не может зафиксировать транзакцию, вся транзакция
aborts.
- Лидер запускает алгоритм Paxos с репликами. Кворум достигается, если большинство реплик отвечают лидеру подтверждением
- Как только координатор убедится, что все участники, включая его самого, готовы, он сообщает всем участникам о
acceptтранзакции (вторая фаза двухфазной фиксации). На этой фазе каждый участник записывает решение о фиксации в стабильное хранилище, и транзакция фиксируется. - Координатор отправляет клиенту хранилища в Cloud Firestore подтверждение о том, что транзакция зафиксирована. Параллельно координатор и все участники применяют изменения к данным.
Когда база данных Cloud Firestore невелика, может случиться так, что один раздел будет владеть всеми ключами в транзакциях M1-M5. В таком случае в транзакции участвует только один участник, и упомянутая ранее двухфазная фиксация не требуется, что ускоряет запись.
Запись в нескольких регионах
В многорегиональной конфигурации распределение реплик по регионам повышает доступность, но сопряжено с ухудшением производительности. Время обмена данными между репликами в разных регионах увеличивается. Следовательно, базовая задержка для операций Cloud Firestore несколько выше по сравнению с однорегиональными конфигурациями.
Мы настраиваем реплики таким образом, чтобы лидерство при разделении данных всегда оставалось за основным регионом. Основной регион — это тот, из которого трафик поступает на сервер Cloud Firestore . Такое решение о лидерстве уменьшает задержку обмена данными между клиентом хранилища в Cloud Firestore и лидером реплики (или координатором для транзакций с множественным разделением).
Каждая операция записи в Cloud Firestore также включает в себя некоторое взаимодействие с механизмом обработки запросов в реальном времени в Cloud Firestore . Для получения дополнительной информации о запросах в реальном времени см. раздел «Понимание запросов в реальном времени в масштабе» .
Поймите жизненный цикл чтения в Cloud Firestore
В этом разделе рассматриваются автономные операции чтения, не требующие обработки в реальном времени, в Cloud Firestore . Внутри системы сервер Cloud Firestore обрабатывает большинство таких запросов в два основных этапа:
- Однократное сканирование диапазона по таблице индексов.
- Точечный поиск в таблице «Документы» на основе результатов предыдущего сканирования.
Чтение данных из уровня хранения осуществляется внутри системы с использованием транзакций базы данных для обеспечения согласованности чтения. Однако, в отличие от транзакций, используемых для записи, эти транзакции не используют блокировки. Вместо этого они работают путем выбора временной метки, а затем выполнения всех операций чтения в эту временную метку. Поскольку они не получают блокировок, они не блокируют одновременные операции чтения и записи. Для выполнения этой транзакции клиент хранения в Cloud Firestore указывает временную метку, которая сообщает уровню хранения, как выбрать временную метку для чтения. Тип временной метки, выбранной клиентом хранения в Cloud Firestore , определяется параметрами чтения для запроса на чтение.
Понимание транзакции чтения на уровне хранения данных.
В этом разделе описываются типы операций чтения и способы их обработки на уровне хранения данных в Cloud Firestore .
Увлекательное чтение
По умолчанию чтение Cloud Firestore осуществляется с использованием строгой согласованности . Эта строгая согласованность означает, что при чтении из Cloud Firestore возвращается последняя версия данных, отражающая все операции записи, выполненные до начала чтения.
Однократное раздельное чтение
Клиент хранилища в Cloud Firestore находит разделы, которым принадлежат ключи строк, подлежащих чтению. Предположим, ему нужно прочитать данные из раздела 3 из предыдущего раздела . Клиент отправляет запрос на чтение ближайшей реплике, чтобы уменьшить задержку при передаче запроса туда и обратно.
На данном этапе в зависимости от выбранной реплики могут произойти следующие события:
- Запрос на чтение направляется ведущей реплике (зона А).
- Поскольку ведущий всегда в курсе последних событий, чтение может продолжаться без остановок.
- Запрос на чтение направляется реплике, не являющейся лидером (например, в Зону B).
- Split 3, возможно, по своему внутреннему состоянию знает, что у него достаточно информации для выполнения операции чтения, и Split это делает.
- Split 3 не уверен, получил ли он последние данные. Он отправляет сообщение лидеру с просьбой указать метку времени последней транзакции, которую необходимо применить для обработки запроса на чтение. После применения этой транзакции чтение может быть продолжено.
Затем Cloud Firestore возвращает ответ своему клиенту.
Многократное разделение чтения
В ситуации, когда чтение необходимо выполнить из нескольких разделов данных, для всех разделов используется один и тот же механизм. После того, как данные будут получены из всех разделов, клиент хранилища в Cloud Firestore объединяет результаты. Затем Cloud Firestore отправляет эти данные своему клиенту.
Застоявшиеся книги
В Cloud Firestore режим чтения по умолчанию — это режим «быстрого чтения». Однако он сопряжен с потенциально большей задержкой из-за необходимости обмена данными с лидером. Часто вашему приложению Cloud Firestore не требуется считывать последнюю версию данных, и эта функция хорошо работает с данными, которые могут быть устаревшими на несколько секунд.
В таком случае клиент может выбрать получение устаревших данных, используя параметр чтения read_time . В этом случае чтение выполняется в том виде, в котором данные были на момент read_time , и ближайшая реплика, скорее всего, уже подтвердила наличие данных на указанный момент read_time . Для заметно более высокой производительности разумным значением для учета устаревших данных является 15 секунд. Даже для устаревших данных возвращаемые строки будут согласованы друг с другом.
Избегайте зон повышенного риска
В Cloud Firestore распределение трафика происходит автоматически, разбивая его на более мелкие части, чтобы при необходимости или при расширении пространства ключей распределить нагрузку по серверам хранения. Части, созданные для обработки избыточного трафика, сохраняются примерно 24 часа, даже если трафик пропадает. Таким образом, при повторяющихся всплесках трафика разделение сохраняется, и при необходимости вводятся новые части. Эти механизмы помогают базам данных Cloud Firestore автоматически масштабироваться при увеличении нагрузки трафика или размера базы данных. Однако следует учитывать некоторые ограничения, описанные ниже.
Разделение хранилища и нагрузки требует времени, а слишком быстрое увеличение трафика может привести к высокой задержке или ошибкам превышения сроков, обычно называемым «горячими точками» , пока сервис адаптируется. Наилучшей практикой является распределение операций по диапазону ключей, при этом наращивая трафик на коллекции в базе данных с частотой 500 операций в секунду. После этого постепенного увеличения трафик следует наращивать до 50% каждые пять минут. Этот процесс называется правилом 500/50/5 и позволяет оптимально масштабировать базу данных в соответствии с вашей рабочей нагрузкой.
Хотя при увеличении нагрузки разделение данных происходит автоматически, Cloud Firestore может разделить диапазон ключей только до тех пор, пока не будет обслуживаться один документ с использованием выделенного набора реплицированных серверов хранения. В результате, большие и постоянные объемы одновременных операций над одним документом могут привести к возникновению «горячей точки» в этом документе. Если вы сталкиваетесь с устойчиво высокими задержками при работе с одним документом, вам следует рассмотреть возможность изменения вашей модели данных для разделения или репликации данных между несколькими документами.
Ошибки конкуренции возникают, когда несколько операций пытаются одновременно читать и/или записывать один и тот же документ.
Еще один особый случай возникновения «горячих точек» происходит, когда в качестве идентификатора документа в Cloud Firestore используется ключ с последовательным увеличением/уменьшением, и при этом выполняется значительно больше операций в секунду. Создание дополнительных разделов здесь не помогает, поскольку всплеск трафика просто перемещается в вновь созданный раздел. Поскольку Cloud Firestore по умолчанию автоматически индексирует все поля документа, такие движущиеся «горячие точки» могут также создаваться в индексном пространстве для поля документа, содержащего значение с последовательным увеличением/уменьшением, например, метку времени.
Обратите внимание, что, следуя описанным выше рекомендациям, Cloud Firestore сможет масштабироваться для обслуживания произвольно больших рабочих нагрузок без необходимости корректировки каких-либо настроек.
Поиск неисправностей
Cloud Firestore предоставляет Key Visualizer в качестве диагностического инструмента, предназначенного для анализа моделей использования и устранения проблем, связанных с возникновением «горячих точек».
Что дальше?
- Узнайте больше о передовых методах.
- Узнайте о запросах в реальном времени в масштабе предприятия.